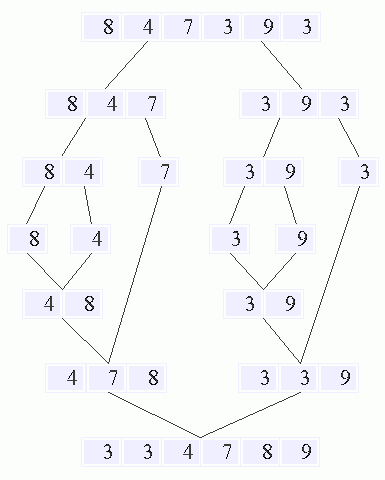
The quicksort algorithm is similar to merge sort in that it takes the same divide and conquer approach that the merge sort algorithm uses. Quicksort works by partitioning an array into two sub-arrays. Merge sort does the same thing, but quick sort does it by seperating the partition around a pivot point. The numbers less than the pivot point are placed into the lower array and those above into a higher array. The function then runs recursively continuing to sort the arrays until they are seperated into fully sorted arrays. The array ends completly sorted and merged back into one array. Quick sort is normally extremely fast in practice, although its worst case scenario running time is O(n^2), but the average case is O(n*logn^2) making it the fastest of the five sorting algorithims looked at.